My #LearnbyDoing Journey with Crio.Do

I came to know about an externship program opportunity by Crio.Do from one of my LinkedIn connections. It’s known as the Crio Winter of Doing #CWoD. I went through their official website and realized that I’ll get a chance to have a good experience in product development if I get into that program and work along with them. The first two stages are for preparation and learning developer essential skills, and the final stage is where I’ll get to work on a real, challenging project.
I have now spent a week learning by doing with Crio.Do. It has been a wonderful week diving deep into software development essential areas like HTTP, REST APIs, Linux, AWS Cloud, and Git. These were all part of Stage 1. I must say, their learning by doing methodology is awesome, effective, and results-driven. I have studied these topics earlier on my own from various resources but the depth I have got by exploring through the documentations that Crio.Do provided was unparalleled.
There are no videos as well as no lengthy tutorials. Each topic is packaged as a micro-experience and has multiple modules in it that give hands-on experience on the subject you are learning. Some reading, exploring, experimenting, writing some code, solving quizzes, and then again going back to reading. This is how Crio.Do takes us through a certain topic. This is what they call #LearnbyDoing.
Some interesting things I’ve learned so far#
You might have encountered the below pop-up once in your life when trying to reload a web page containing a form. Do you know why this happens?
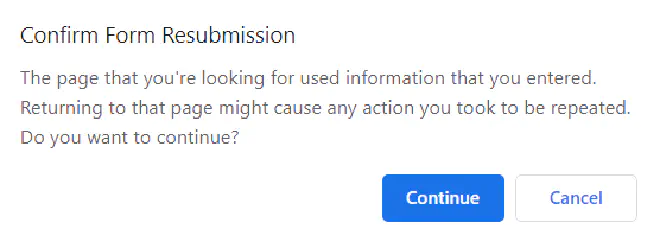
This happens when the user tries to refresh or use the back button to navigate back to an HTTP POST. There is a way around it. Read this article to know-how: The Post/Redirect/Get (PRG) Pattern
I have also learned how to use piping using the | pipe operator in the bash shell. Piping is used to feed the output of a command to the input of another command. Here is an example below:
cat /proc/meminfo | wc | awk '{print $1}'
The meminfo file inside the proc directory contains memory utilization details in Linux. I used cat to display the contents of the file, piped this output to wc command that prints newline, word, and byte counts, and finally used awk to split the output of the wc command. awk uses whitespace as a separator to split the input line. After the split happens $1 points to the first variable that contains the newline count.
When you’re stuck with a problem…#
I had deployed a food ordering app on the AWS cloud. There was a task given to me yesterday (screenshot below). It was to perform data analysis on the AWS server log using bash commands.
I wrote the below one-liner command in bash but it failed to give me the expected output.
grep -E -o "([0-9]{1,3}[\.]){3}[0-9]{1,3}" /var/log/qeats-server.log |
sort | uniq -c | while read line || [[ -n $line ]];
do NUM=$(awk '{print $1}' <<< $line); IP=$(awk '{print $2}' <<< $line);
CITY=$(curl -s https://tools.keycdn.com/geo.json?host=$IP |
python3 -c "import sys, json; print(json.load(sys.stdin)['data']['geo']['city'])");
echo "$CITY, $NUM"; done;
grep fetches all the IP addresses in the log file. I sorted the list of IP addresses so that uniq can work on it and display only the unique IP addresses. I have used -c flag with uniq to also get the number of occurrences of an IP which means the number of requests a user having that IP has made. The while loop is responsible for reading each line and printing the city name of the corresponding IP addresses along with the number of requests. Now here comes the problem. Different IP addresses might belong to the same location and they would get printed more than once.
San Francisco, 1
San Francisco, 1
Kolkata, 17
Columbus, 30
Kolkata, 6
St Petersburg, 3
We want a solution that would add all the number of requests originating from a city.
San Francisco, 2
Kolkata, 23
Columbus, 30
St Petersburg, 3
We can use hash maps for this. I ended up writing a python script embedded in a bash script and it worked fine. It took a good amount of time to figure out how to embed a python script in a bash script.
Here is the working bash script:
#!/bin/bash
grep -E -o "([0-9]{1,3}[\.]){3}[0-9]{1,3}" /var/log/qeats-server.log | sort | uniq -c > output.txt
function printCities
{
python3 - <<HERE
import requests, json, os
file_output = open('output.txt', 'r')
raw_data = file_output.readlines()
data = []
j = 0
for i in range(0, len(raw_data)):
raw_data[i] = raw_data[i].lstrip().strip()
data.append(raw_data[i].split(" ")[0])
data.append(raw_data[i].split(" ")[1])
data_dict = {}
url = "https://tools.keycdn.com/geo.json?host="
for i in range(0, len(data), 2):
response = requests.get(url + data[i+1])
json_response = response.json()
city = json_response['data']['geo']['city']
if city in data_dict.keys():
data_dict[city] += int(data[i])
else :
data_dict[city] = int(data[i])
if None in data_dict.keys():
del data_dict[None]
for k, v in data_dict.items():
print(k + ", " + str(v))
HERE
}
cities=$(printCities)
echo "$cities"
I have made use of heredoc in bash to pass multi-line python code to python3 and get the output of the python code in bash.
I have shared the log here in a zip file. You can try to solve it on your own or test my solution. Getting the log file from the server was another challenge I faced. I couldn’t find any option to download logs from the AWS management console. So, I logged into my GitLab account using SSH in the terminal connected to the AWS EC2 instance to upload the log file to my repo. When I tried to push it, the remote rejected it. I realized that it may be because the log file was huge (around 38k lines). So, I had to split it into multiple files each containing 1000 lines.
cat /var/log/qeats-server.log > aws-log.txt
# bash command to split a file
split aws-log.txt --additional-suffix=.txt
The zip file contains the split files. You have to merge them back to a single file and then perform the data analysis task on it. I don’t think there can be a better way than to use cat (short for concatenate) to join the files.
# the split log files all start with x
# concatenate all of them and
# redirect the output to log.txt
cat x* > log.txt
Now you can use this log file to do whatever you want.
To sum it up, I have learned a bunch of new bash commands, how and when to use them. I was again made to realize how powerful the Linux terminal is. Also, got a better idea about HTTP and REST APIs. I am excited and looking forward to learning more in the upcoming stages. I’m thankful to Crio.Do to make the journey smooth and interesting so far.
Anyone who stops learning is old, whether at twenty or eighty. Anyone who keeps learning stays young.
Henry Ford