Performance Optimization using Pivot Tables Technique in MySQL

Making a database call is an expensive operation. It involves opening a connection to the database, and the SQL query passed through this connection to the database is parsed, optimized, and then finally executed.
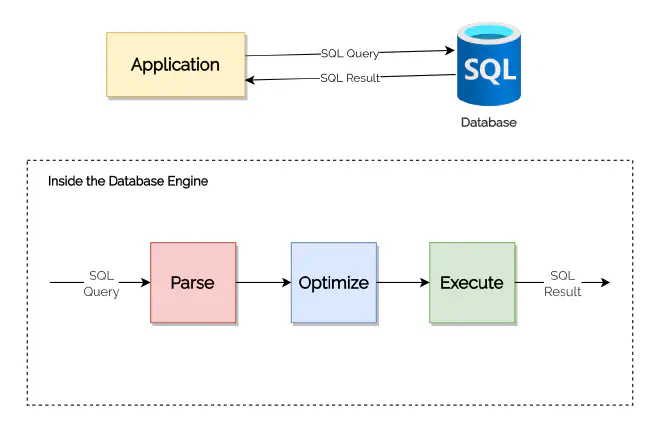
The process of opening a new connection to the database takes a significant amount of time and space. If we keep on opening new connections every time for each new request to our application, it would take a lot of time to send the response back and would also exceed our memory resources. To solve this problem, we use some connection pooling mechanisms to open/close, reuse and maintain connections to the database. Spring Boot by default uses HikariCP, which is a connection pooling tool. This means that the web application doesn’t have to face any delay in serving response due to managing database connections.
So that’s one problem solved. But what if you’ve written a SQL query that is not fast enough, or you’re hitting the database with multiple SQL queries, that otherwise could have been grouped?
We’ll discuss a similar problem statement and look at how we can solve it.
Problem Statement#
Suppose we’ve got a requirement where we need to fetch data on the basis of some conditions. Have a look at this part of an API request body:
{
"current_status": "F, C"
}
We need to fetch the count of enquiries from the cm_enquiry table for each creator_id. We want the count as per our current_status value. Like the count for “F”, the count for “C” and so on.
The naive solution would be to write separate SQL queries for them.
select creator_id, count(*)
from cm_enquiry
where current_status = 'F'
group by creator_id;
select creator_id, count(*)
from cm_enquiry
where current_status = 'C'
group by creator_id;
We might have more current_status values passed in the request. And, if we continue hitting the database with such queries that fetch data on the basis of only one current_status value at a time then it would take a lot of time to finish the process of executing all of those queries and sending back the response.
We should write a query that can fetch all the required data at once.
Solution#
Let’s consider this below query. It is a single query that can fetch all the required data at once.
select creator_id, current_status, count(*)
from cm_enquiry
where current_status in ('F', 'C')
group by creator_id, current_status;
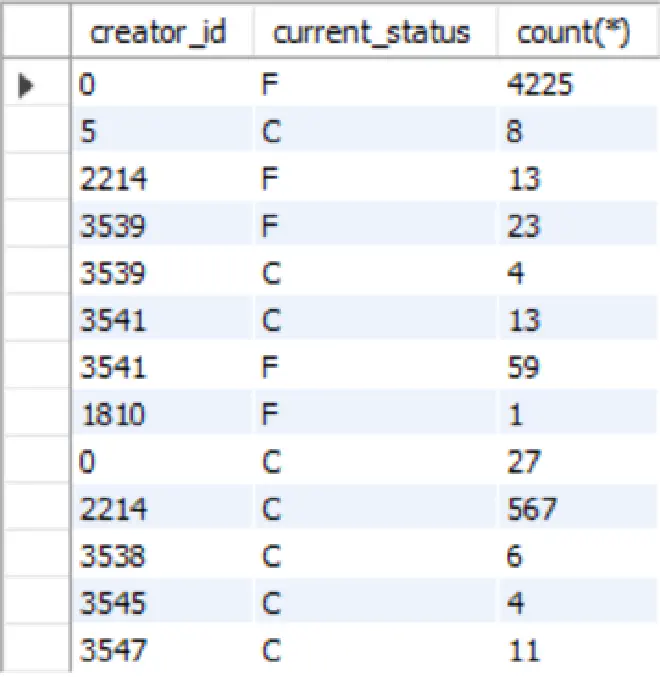
If you look carefully at the result, the creator_id is getting printed for every current_status value. Also, if you think about the code (say in Java) to parse this result table, it would be messy.
A much better solution is to use the Pivot Tables technique. This technique transforms the table data from rows to columns. The below query implements it.
select creator_id,
count(if(current_status = 'F', 1, null)) as 'F',
count(if(current_status = 'C', 1, null)) as 'C'
from cm_enquiry
group by creator_id;
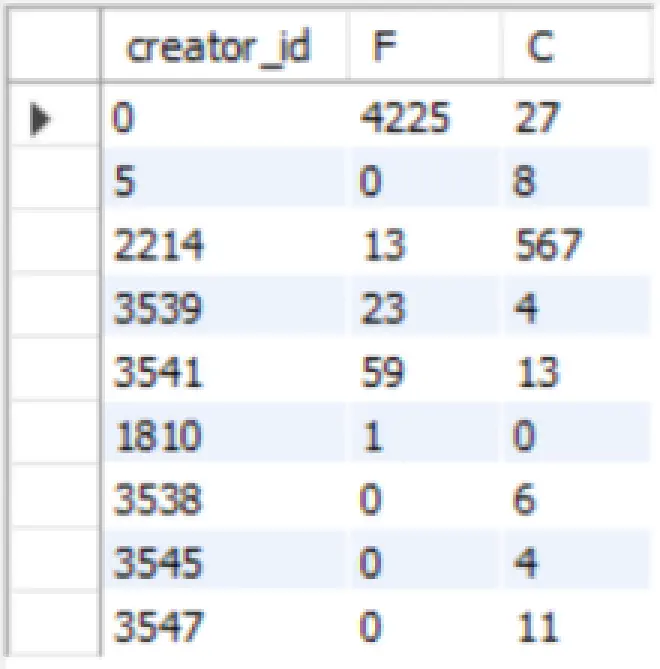
This query scans each row in the table and if the condition inside the count function gets satisfied then the if function returns 1 otherwise null. So for every satisfied condition, the count gets incremented by 1. All the count data gets displayed under specific columns.
We could have also used the sum function instead of the count function.
select creator_id,
sum(if(current_status = 'F', 1, 0)) as 'F',
sum(if(current_status = 'C', 1, 0)) as 'C'
from cm_enquiry
group by creator_id;
Here the sum function would add 1 when the condition gets satisfied, otherwise 0.
The Pivot Tables technique made the SQL result table look cleaner and easier to parse. This way we can reduce the number of calls to the database and hence optimize the performance of our application.
[This article mention the frameworks and tools that I’ve used in my project. One doesn’t need to have prior knowledge about them to understand this article. The only prerequisite to this article is to know SQL.]